大模型时代:AI应用开发入门指南
过去 20 年,几次科技浪潮,让人们意识到,赶上趋势,抓住科技发展新机遇,对自身发展至关重要。随着大模型的爆发,人们趋之若鹜,都不愿意错过时代发展的红利和机遇。那么如何开始学习 AI,开始大模型领域知识的学习呢?
本系列文章,从我自身经验讲起,总结过去一段时间的学习内容,供有兴趣的人参考。
说明:本文部分内容是我学习 AGIClass,孙志岗老师的大模型全栈课的相关笔记。如果读者有兴趣可以去学习原版课程内容。在此,我也特别强烈的推荐孙志岗老师的相关课程。
在这个AI快速发展的时代,我们经常听到AGI、大模型、ChatGPT这些词汇。作为技术从业者或对AI感兴趣的朋友,你可能会问:我该如何参与这场技术革命?
迎接 AGI 时代
AGI(Artificial General Intelligence)中文译为「通用人工智能」。是具备超越人类智能的 AI。
实现 AGI 是所有 AI 核心厂商的共同目标。其他人的期望:
- 在过程中能抓住一些机会
- 在 AGI 到来后成为获益者
AGI 多久会到来?
- 乐观预测:明年
- 主流预测:3-5 年(OpenAI、DeepMind、NVIDIA 持此观点)
- 悲观预测:10 年
AGI 时代,AI 无处不在,形成新的社会分层:
- AI 产品使用者,使用别人开发的 AI 产品
- AI 产品制造者,设计和开发 AI 产品,哪怕只是满足自己的需求
- 基础模型相关,训练基础大模型,或为大模型提供基础设施(算力等)
越向下层,重要性越高,从业人数越少。
AI 产品制造者的核心能力模型
三懂:
- 懂业务,就是懂用户、懂客户、懂需求、懂市场、懂运营、懂商业模式,懂怎么赚钱
- 懂 AI,就是懂 AI 能做什么,不能做什么,怎样才能做得更好、更快、更便宜,懂怎么用 AI 解决赚钱过程中的问题
- 懂编程,就是懂如何编写代码实现一个符合业务需求的产品,尤其是 AI 产品
争取三懂,至少两懂,无论如何要懂 AI。所以有三种人:
- AI 全栈工程师:懂业务、懂 AI、懂编程
- 业务向:懂业务、懂 AI
- 编程向:懂编程、懂 AI
建议:
- 编程向的,要尽可能靠近业务,争取全栈,否则走不远
- 业务向的,试试学编程,自主性更强。AI 编程,门槛已经低多了(但绝不是没门槛)
什么是 AI?

「深蓝」的创造者许峰雄曾和孙志岗面对面说过:「AI is bullshit。深蓝没用任何 AI 算法,就是硬件穷举棋步。」
一种观点:基于机器学习、神经网络的是 AI,基于规则、搜索的不是 AI。
大模型能做什么?
大模型(Large Language Model,简称LLM)的能力远超出了简单的对话。以下是一些典型应用场景:
1. 结构化输出
- 信息抽取
- 数据分类
- 文本聚类
2. 智能交互
- 持续对话
- 决策辅助
- 技术方案设计
3. 创意生成
- 文案创作
- 代码生成
- 多语言翻译
可能一切问题,都能解决,所以是通用人工智能 AGI
用 AI,要用「用人思维」:
- 机器思维:研发了什么功能,就有什么功能。
- 用人思维:给 ta 一个任务,总会有些反馈,或好或坏,惊喜或惊吓。
- 大模型就是一个函数,给输入,生成输出
- 任何可以用语言描述的问题,都可以输入文本给大模型,就能生成问题的结果文本
- 进而,任意数据,都可以输入给大模型,生成任意数据
英伟达 CEO 黄仁勋 2024 年 6 月 2 日在 Computex 上的演讲提到各种模态数据的统一支持:

大模型是怎样工作的?
通俗原理
其实,它只是根据上文,猜下一个词(的概率)……

OpenAI 的接口名就叫「completion」,也证明了其只会「生成」的本质。
下面用程序演示「生成下一个字」。你可以自己修改 prompt 试试。还可以使用相同的 prompt 运行多次。
1 | from openai import OpenAI |
开心,
因为我很期待明天
明天是个全新的一天
有数不尽的可能性等着我
我可以充满激情地迎接新的挑战
我可以抓住每一次机会
让自己变得更强大
我可以满怀希望地面对未来
相信自己能够实现梦想
今天的快乐会成为明天的动力
让我更加勇敢地追求美好的生活
无论遇到什么困难
我都会坚持不懈
勇敢前行,努力奋斗
因为明天的希望就在前方
我相信明天会更加美好
所以今天,我感到无比幸福和满足。
略深一点的通俗原理
训练和推理是大模型工作的两个核心过程。
用人类比,训练就是学,推理就是用。学以致用,如是也。
例如,有下面训练数据:
- AI 正在改变我们的生活方式。
- AI 技术在医疗领域有广泛应用。
- AI 可以提高企业的生产效率。
- AI 算法能够预测市场趋势。
- AI 在自动驾驶汽车中扮演重要角色。
- AI 有助于个性化教育的发展。
- AI 机器人可以执行复杂的任务。
- AI 技术正在推动智能家居的普及。
- AI 在金融分析中发挥着关键作用。
- AI 技术正逐步应用于艺术创作。
「AI」之后出现「技」的概率大于其它字。这些字之间的概率关系,就是大模型训练时学到的。
用不严密但通俗的语言描述原理:
- 大模型阅读了人类说过的所有的话。这就是「机器学习」
- 训练过程会把不同 token 同时出现的概率存入「神经网络」文件。保存的数据就是「参数」,也叫「权重」
- 我们给推理程序若干 token,程序会加载大模型权重,算出概率最高的下一个 token 是什么
- 用生成的 token,再加上上文,就能继续生成下一个 token。以此类推,生成更多文字
Token 是什么?
- 可能是一个英文单词,也可能是半个,三分之一个
- 可能是一个中文词,或者一个汉字,也可能是半个汉字,甚至三分之一个汉字
- 大模型在开训前,需要先训练一个 tokenizer 模型。它能把所有的文本,切成 token
- AI 做对的事,怎么用这个原理解释?
- AI 的幻觉,一本正经地胡说八道,怎么用这个原理解释?
再深一点点
- 这套生成机制的内核叫「Transformer 架构」
- Transformer 是目前人工智能领域最广泛流行的架构,被用在各个领域
- Transformer 仍是主流,但并不是最先进的
| 架构 | 设计者 | 特点 | 链接 |
|---|---|---|---|
| Transformer | 最流行,几乎所有大模型都用它 | OpenAI 的代码 | |
| RWKV | PENG Bo | 可并行训练,推理性能极佳,适合在端侧使用 | 官网、RWKV 5 训练代码 |
| Mamba | CMU & Princeton | 性能更佳,尤其适合长文本生成 | GitHub |
| Test-Time Training (TTT) | Stanford, UC San Diego, UC Berkeley & Meta AI | 速度更快,长上下文更佳 | GitHub |
目前只有 transformer 被证明了符合 scaling-law。
用好 AI 的核心心法
OpenAI 首席科学家 Ilya Sutskever 说过:
数字神经网络和人脑的生物神经网络,在数学原理上是一样的。
所以,我们要:
把 AI 当人看
把 AI 当人看
凯文·凯利,和孙志岗老师,都提到过类似的观点:「和人怎么相处,就和 AI 怎么相处。」
- 用「当人看」来理解 AI
- 用「当人看」来控制 AI
- 用「当人看」来说服别人正确看待 AI 的不足
当什么人呢?
- 学习时当老师
- 工作时当助手
- 休闲时当朋友
这是贯彻整门课的心法,乃至我们与 AI 相伴的人生的心法。
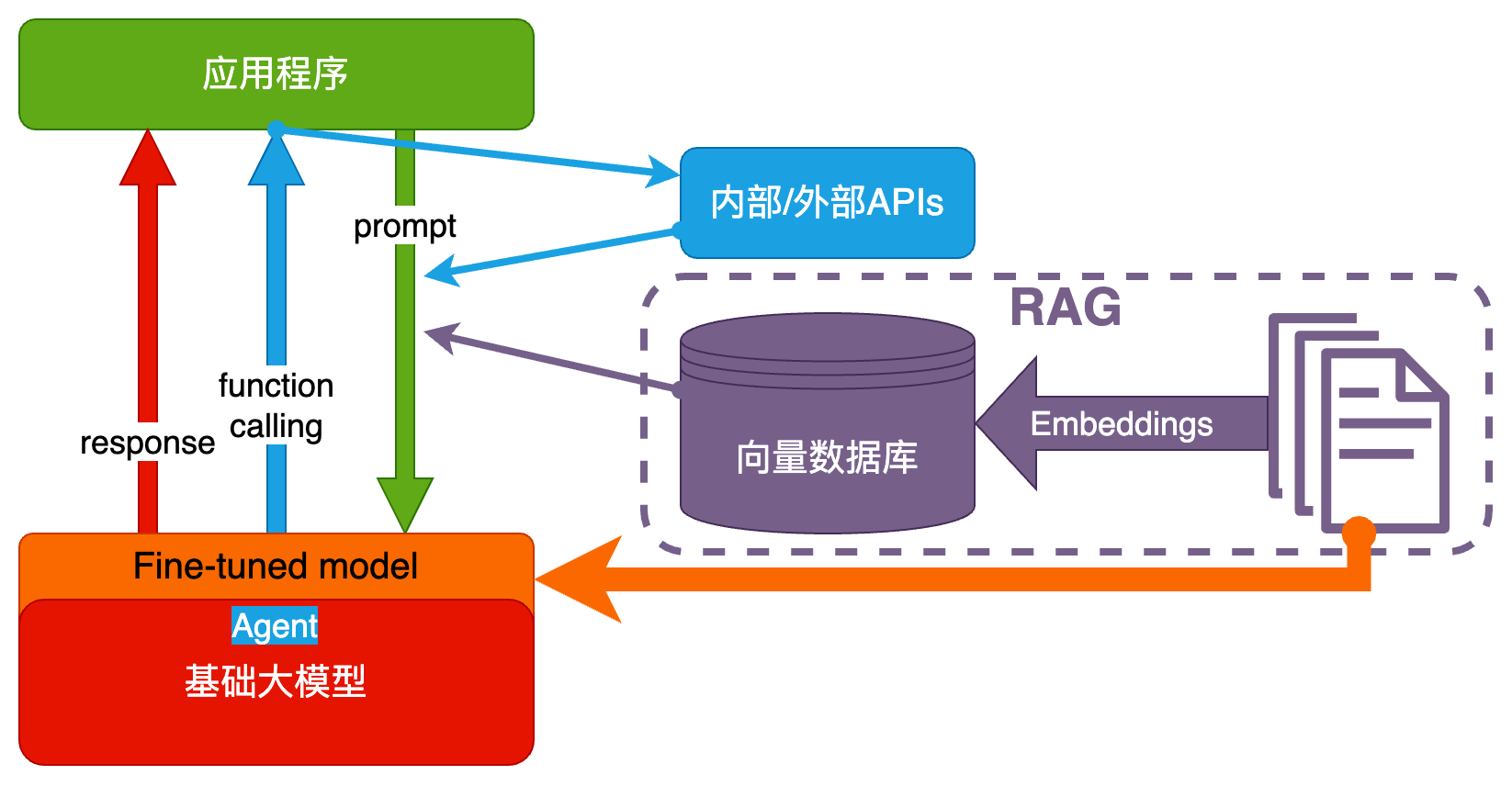
大模型应用产品架构
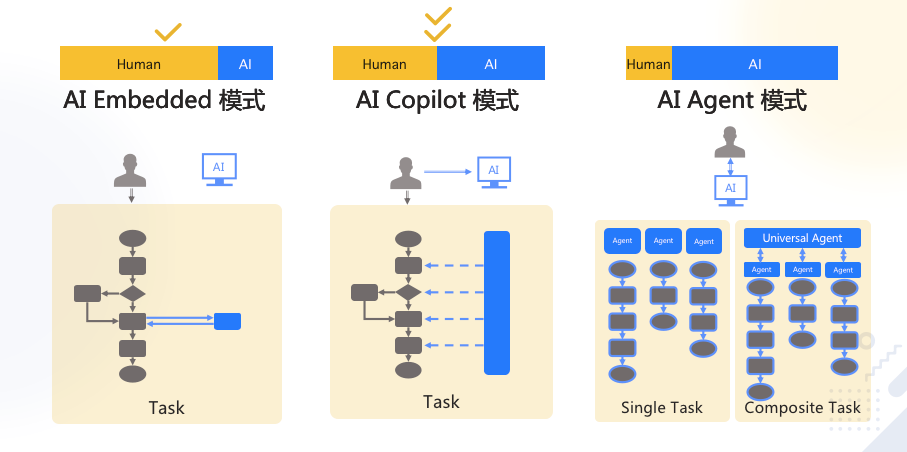
Agent 模式还太超前,Copilot 是当前主流。
实现 Copilot 的主流架构是多 Agent 工作流
- 模仿人做事,将业务拆成工作流(workflow、SOP、pipeline)
- 每个 Agent 负责一个工作流节点
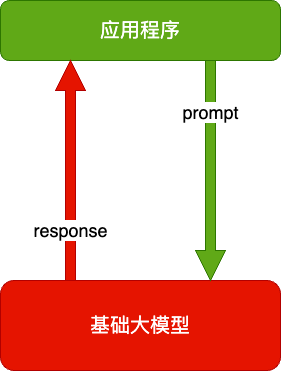
大模型应用技术架构
纯 Prompt
- Prompt 是操作大模型的唯一接口
- 当人看:你说一句,ta 回一句,你再说一句,ta 再回一句……
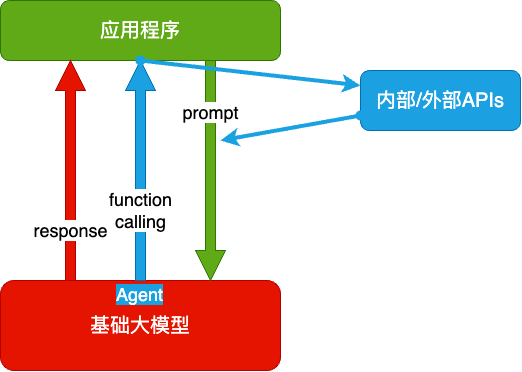
Agent + Function Calling
- Agent:AI 主动提要求
- Function Calling:AI 要求执行某个函数
- 当人看:你问 ta「我明天去杭州出差,要带伞吗?」,ta 让你先看天气预报,你看了告诉 ta,ta 再告诉你要不要带伞
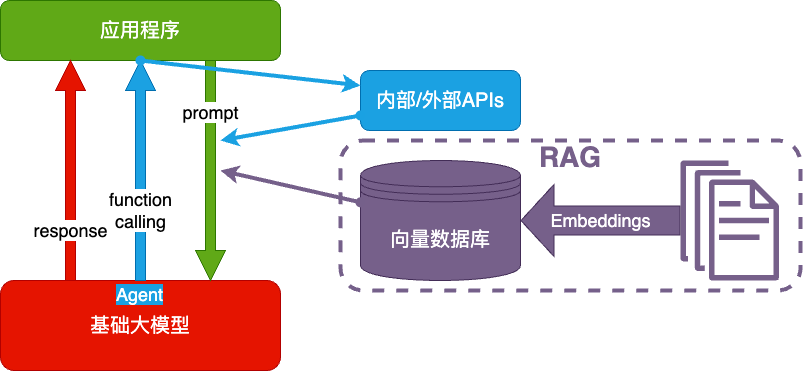
RAG(Retrieval-Augmented Generation)
- Embeddings:把文字转换为更易于相似度计算的编码。这种编码叫向量
- 向量数据库:把向量存起来,方便查找
- 向量搜索:根据输入向量,找到最相似的向量
- 当人看:考试答题时,到书上找相关内容,再结合题目组成答案,然后,就都忘了
Fine-tuning(精调/微调)
当人看:努力学习考试内容,长期记住,活学活用。
如何选择技术路线
面对一个需求,如何开始,如何选择技术方案?下面是个不严谨但常用思路。
其中最容易被忽略的,是准备测试数据
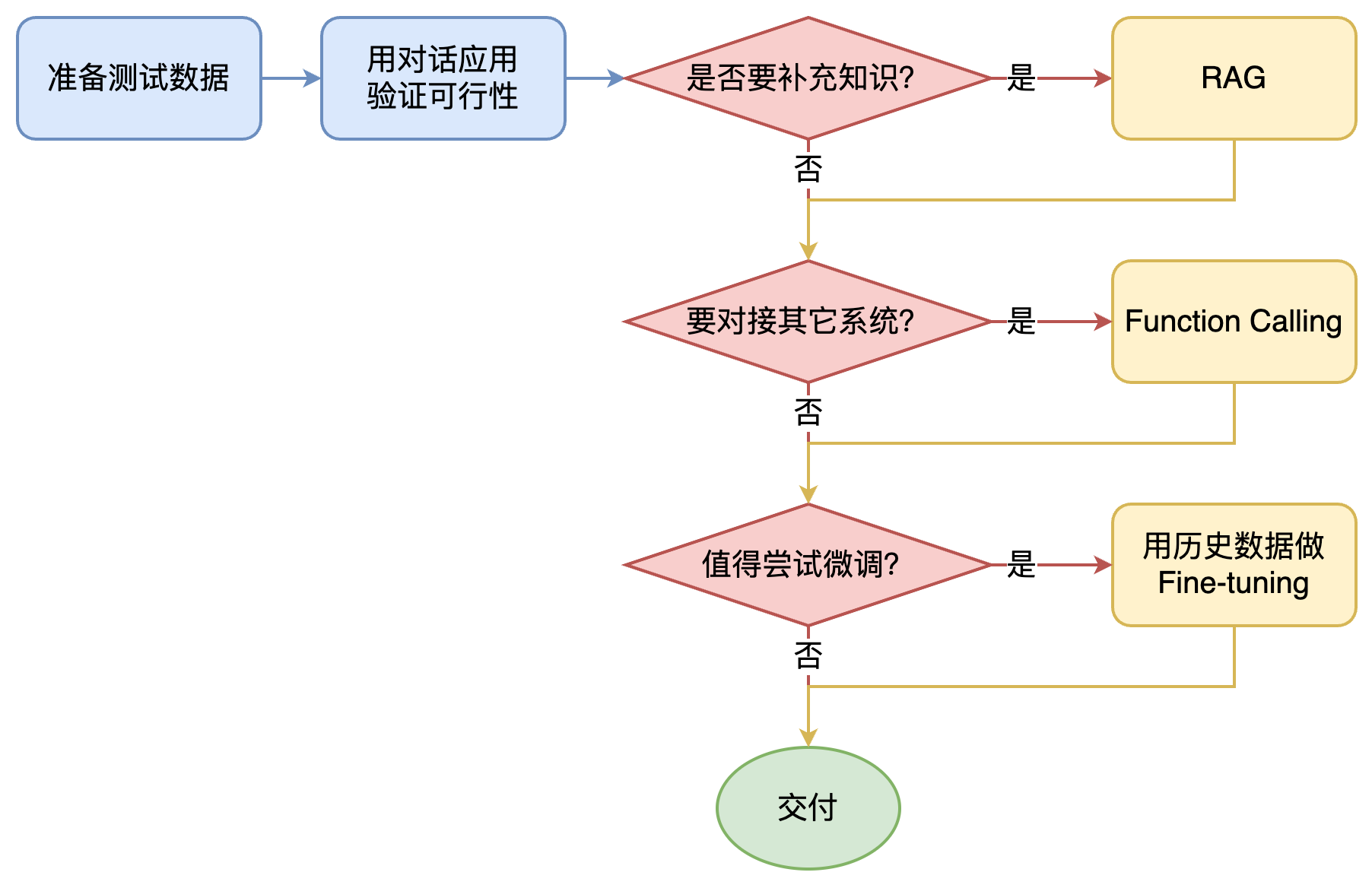
值得尝试 Fine-tuning 的情况:
- 提高模型输出的稳定性
- 用户量大,降低推理成本的意义很大
- 提高大模型的生成速度
- 需要私有部署
如何选择基础模型
凡是问「哪个大模型最好?」的,都是不懂的。
不妨反问:「有无论做什么,都表现最好的员工吗?」
基础模型选型,合规和安全是首要考量因素。
| 需求 | 国外闭源大模型 | 国产闭源大模型 | 开源大模型 |
|---|---|---|---|
| 国内 2C | 🛑 | ✅ | ✅ |
| 国内 2G | 🛑 | ✅ | ✅ |
| 国内 2B | ✅ | ✅ | ✅ |
| 出海 | ✅ | ✅ | ✅ |
| 数据安全特别重要 | 🛑 | 🛑 | ✅ |
然后用测试数据,在可以选择的模型里,做测试,找出最合适的。
为什么不要依赖榜单?
- 榜单已被应试教育污染。唯一还算值得相信的榜单:LMSYS Chatbot Arena Leaderboard
- 榜单体现的是整体能力。放到一件具体事情上,排名低的可能反倒更好
- 榜单体现不出成本差异